Redis和Hazelcast对比
Maybe your NoSQL or relational database is proving hard to scale or is performing badly. Place Hazelcast in-line as a cache or completely replace it.
Rethinking Redis?
Hazelcast和Redis初看起来很相似。它们都能处理相似的用户场景,很难抉择使用哪一种。以下是它们的不同之处。
- Caching
- Clustering
- Querying
- Streaming
- Compute
首先,Redis是一个非常流行的开源项目并且使用广泛。如果我们的使用场景不需要集群,查询和计算,仅仅是简单的缓存的话,我们可以继续使用Redis,作为一个单实例缓存,Redis是一个很好地选择。
显然,我们认为Hazelcast也是相当特别的,接下来让我们看一下Hazelcast和Redis的不同之处。
Caching
Hazelcast能提供更多的缓存模式
Hazelcast和Redis都可以作为缓存使用。缓存是指将慢存储(通常指磁盘)里的数据放到内存中。慢存储可以是关系型数据库,Mainframe,NoSQL数据库或是应用API。为了加速数据的访问,当我们从慢存储将数据读取出来的时候会将数据放入缓存。
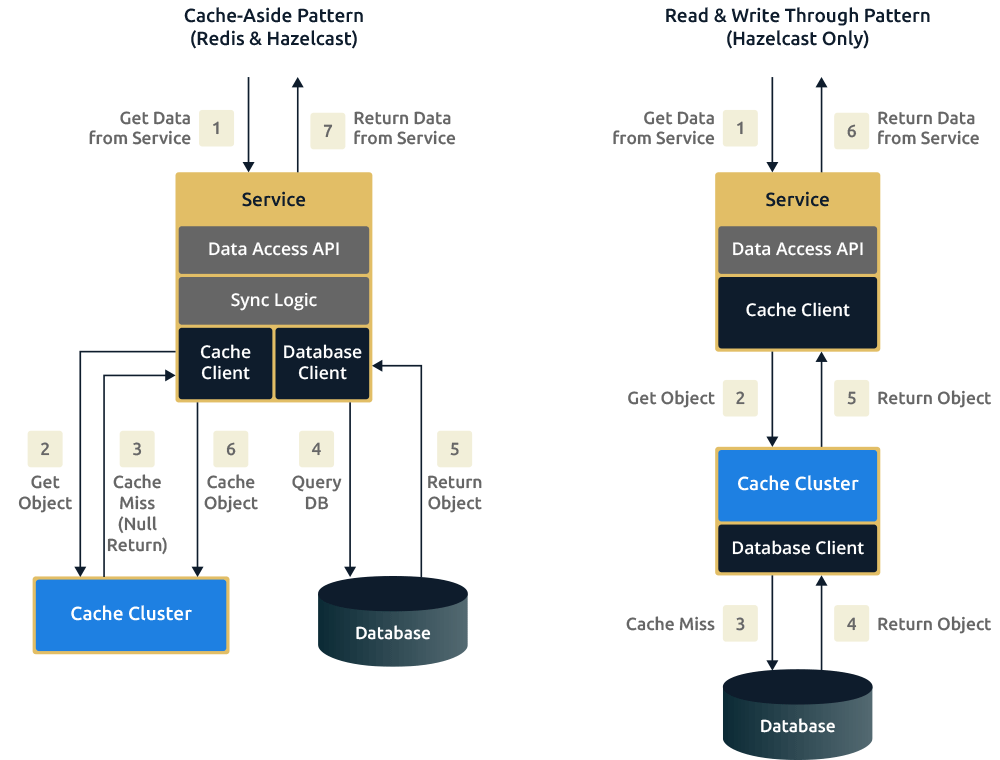
Hazelcast和Redis在缓存使用场景的最大区别是Redis只提供一种缓存模式,而Hazelcast提供多种缓存模式。使用Redis作为其他存储(比如数据库)的缓存,只能使用cache-aside模式,这种模式引入了额外的网络消耗。而Hazelcast可以进行配置,当出现缓存未命中时可以使用read-through模式;当缓存需要更新时可以使用write-through模式。使用Redis的话,需要开发者去写缓存/数据库同步的逻辑,并且需要开发者去编码实现更新/读取数据库的操作。而对于Hazelcast来说,只有更新/读取的逻辑是需要开发者做的,这就使得代码更加简洁易懂。Hazelcast既能使用cache-aside模式,也能使用read-through,write-through和write-behind的缓存模式。
下图展示了使用cache-aside模式和read-through/write-through模式的请求流对比。需要着重强调的是使用read-through/write-through模式访问缓存的时候,开发所需要的逻辑和依赖库大大减少,缓存过程本身去处理逻辑和数据库的连接。而使用cache-aside模式的话意味着开发者需要自己去处理这些。假设有很多不同的应用都要去处理数据库的访问和缓存,那么系统就会变得很复杂并且在生产环境中很难处理。而使用分布式缓存区处理这些就简单多了。这些模式使得实现Cache as a Service更加简单。
最后,让我们来谈一谈write-behind模式。Hazelcast支持这种模式。write-behind模式可以说是write-through模式的扩展。write-bebind模式解决的问题是:写入一个速度很慢的后台存储,比如一个过载的关系型数据库。使用write-behind模式的时候,服务或者应用将数据提交到分布式缓存,在分布式缓存将数据提交到后台存储之前立即返回一个响应。分布式缓存将数据放到队列中,该队列由一个单独的线程在稍后的某个时间点进行读取,分布式缓存会处理好将数据提交到后台存储。使用这种方式,一个慢的后台存储不会给应用带来延迟。对比来说,write-through模式会阻塞响应的返回给调用者,直到后台存储确认了这次提交。由于Redis是单线程的,所以并不支持这种模式。
Clustering
Hazelcast的大部分集群操作可以自动处理,而Redis则需要人工干预
Redis和Hazelcast提供集群的方式有很大不同。集群是一种能够提供扩展性、扩大空间和处理数据能力的一种技术,被用于单一进程无法处理或需要冗余(通常指高可用HA)的情况。集群技术通过将多个进程协调在一起组成一个集群来工作。集群可以跨多机器部署并当一台机器出现问题时提供容灾能力。集群的进程通常是指节点或成员。Redis集群通常基于一台机器的多个核,因为Redis是单线程的。Hazelcast是多线程的,所以Hazelcast集群通常是为了使用更多的内存。
Hazelcast从创建之初就是以内存分布式数据存储为目标,Redis并不是。高可用、自动分区(auto-partitioning)、自动发现(auto-discovery)都被构建在每个Hazelcast成员的核心。
Hazelcast集群中的每个成员都会维护一部分Primary和replica的entries,集群没有主进程和备份进程的概念,这使得架构更加容易。而Redis集群有主节点和备份节点。Redis集群通过sharding提供高可用和扩展性,它将一个大的数据集切割存储到多个节点上。Hazelcast集群通过partitioning实现这种能力。然而,但一个节点离开Redis集群的时候,必须手动做resharding和recovery。在Redis集群中添加和移除节点同样是手动操作。以上所有这些,Hazelcast集群都能自动完成。
Querying
Hazelcast能够理解复杂的obeject graphs并提供查询API, Redis不支持
Redis和Hazelcast都提供key/Value数据结构,但是查询的方式则相当不同。查询是指当我们不知道key的时候获取数据的能力,我们通过指定value的特殊properties来查询。
Redis和我Hazelcast查询最根本的不同是Hazelcast能存储复杂对象并且理解object graph。Redis不支持这种方式,Redis只能通过开发者对复杂的graph建模成一系列的key/value entries,每个key代表一个属性。Redis不支持通过表的概念来区分数据,所有的数据都存储在同一个namespace下。
Hazelcast提供Predicate API和类SQL语句来查询数据。查询API可以用于复杂对象和JSON。Hazelcast也支持灵活的namespace,可以有多个Maps并且分别命名,例如Customer, Invoice, Orders。这种方式避免了污染键的命名空间。
下面是一段简单的在Hazelcast Map上进行的类SQL的查询。
IMap<String, Employee> map = hazelcastInstance.getMap("employee");
Set employees = map.values(new SqlPredicate("active And age < 30"));
最后,Redis原生不支持索引,应用程序员需要自己创建他们自己的索引结构更自己更新。
Hazelcast原生支持索引。索引可用通过配置文件(XML/YAML)或者通过API动态应用。所以可以被用于任意level的object graph。Hazelcast也支持复合索引。
Streaming
Redis支持pub-sub messaging到分布式流数据,而Hazelcast支持Full Straming Stack
流式平台需要多个构建块:
- messaging到分布式流数据
- 在数据流之上构建连续应用的Processing API
- 集成到遗留的非流式系统的连接器
从版本5开始,Redis开始支持Redis Streams: 基于pub-sub的messaging。Redis Streams是仅追加的基于log的存储,能够保留插入顺序并允许非破坏性读。多个消费者可以多次读取和重放数据,数据和顺序都不会改变。重放有序的流对于容错和可扩展性来说是最基础的,Redis Streaming在Streaming技术栈中作为messaging layer是很合适的。
Hazelcast支持streaming技术栈中的所有三个关键组件。首先,Hazelcast Jet是一个支持有状态操作的分布式流式处理引擎。我们可以通过event-time语义使用它来join和聚合数据流,并保证端到端执行性一次。Jet包含很多连接器,比如说CDC,能够将关系型数据库转换成change event的stream。最常用的使用场景是连接器从数据库,JMS或Kafka中将数据流化。基于新事件的触发,Jet运行了一个连续的查询并将结果推送到缓存,保证数据是最新的。
Compute
Redis支持Lua脚本,Hazelcast支持Java并且很快将支持Python和C++
撇开语言的不同,Redis和Hazelcast都支持在集群的某个含有指定数据的节点上直接执行函数。例如,在Hazelcast集群中含有指定key的节点上,可以直接执行一段Java程序。Redis中也是可以实现的。不同之处是Hazelcast节点上的Java程序能够访问集群中其他节点的数据,而Redis集群和Lua脚本无法做到。
另外,Hazelcast提供Entry Processor模式。这是一种允许在一个Map运行function的框架,Hazelcast负责管理在集群的所有节点上运行function,或者可以指定满足key predicate的集群节点上。